言之有度 · 表达优化助手
言之有度 · 表达优化助手
一个纯前端的「多模型并行生成 + 横向对比择优」表达优化小工具。
在线体验:https://yzyl.codelong.top
项目地址: https://github.com/niko-long/yzyl
写这个项目的起因很简单:日常工作里,技术同学经常会写出像
「这个需求改起来很麻烦,你们产品能不能想清楚再来?」
这种「意思没错,但说出来容易得罪人」的话。我一开始用 ChatGPT 直接帮我润色,问题是单次结果只有一种风格,想换一个味道又得重新提问。索性自己撸一个:一次生成多个候选版本,横着摆开比一比,挑一个最顺眼的直接复制走。
整个项目零后端,纯静态三件套(index.html / styles.css + 几个 .js),打包到 nginx 容器里就能跑。
一、它能做什么
一句话:把你想说的话扔进去,结合「场景 / 对方身份 / 语气 / 维度滑块」,并行调用 LLM 生成 N 个优化版本,横向对比。
主界面长这样:
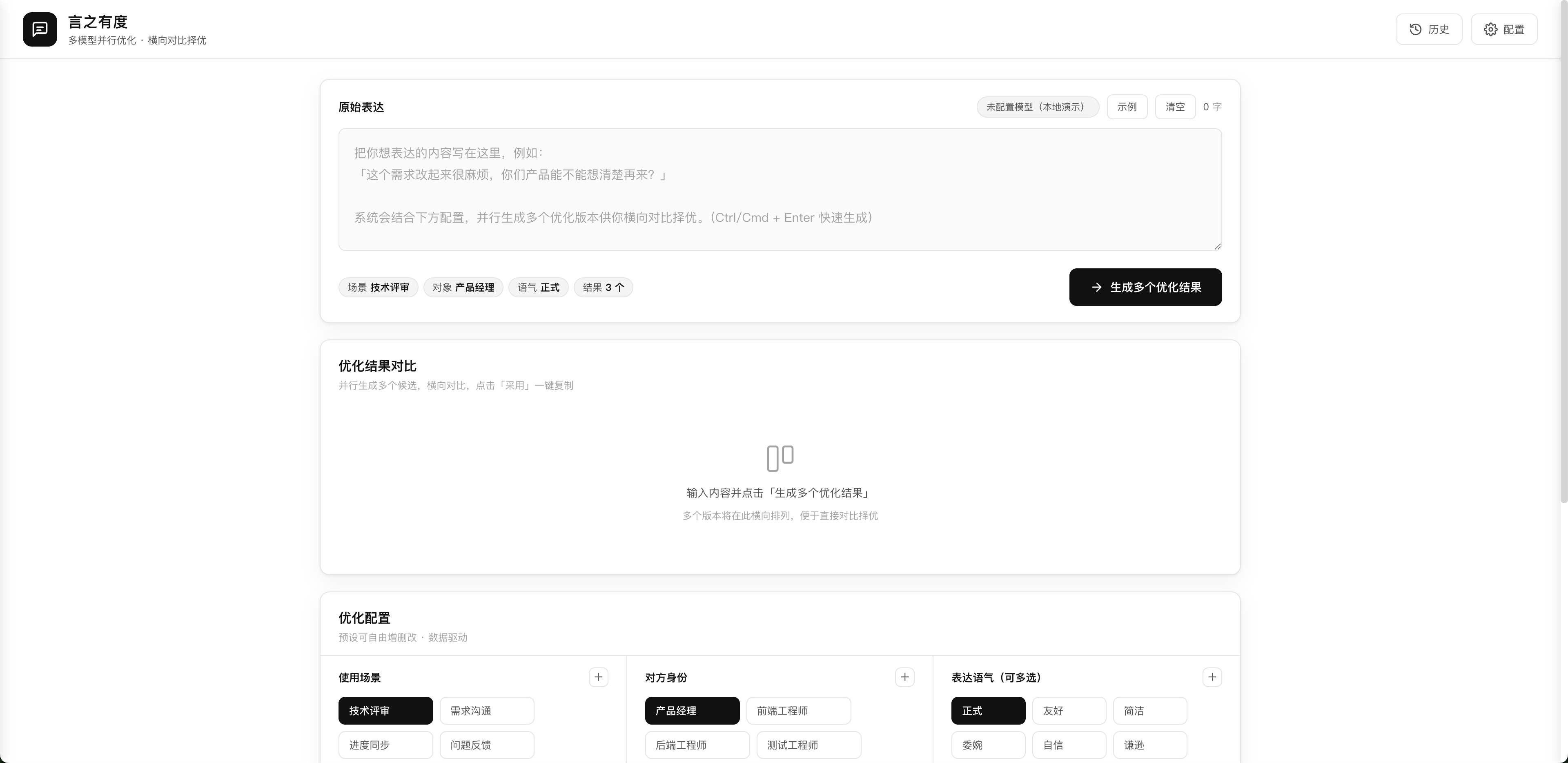
特点提炼:
- 并行而不是串行:一次请求出 3~5 个候选,横向对比。多样性靠不同的
temperature,不是简单调一次切结果。 - 数据驱动的预设:场景 / 身份 / 语气全部可增删改查,存在
localStorage,不需要改代码。 - 维度滑块(0–100):技术深度、术语密度、信息详尽度、共情程度、直接程度,五个档位告诉模型「往哪边偏一点」。
- 完全本地化的密钥:API Key 只存浏览器,不上传任何后端(这个项目本来就没有后端)。
- 零依赖:没有打包工具、没有 npm install、没有框架。一份
index.html+ 三个.js+ 一份.css,浏览器双击都能开。
二、为什么不直接用 ChatGPT 网页版
这是我自己用了一段时间后的对比,给个直观的感受:
| 维度 | ChatGPT / 通义 / Kimi 网页版 | 言之有度 |
|---|---|---|
| 单次产出 | 一段 | 一次 N 段(默认 3,最多 5) |
| 风格切换 | 重新追问、再来一轮 | 不同温度并行,刷新即得新组合 |
| 场景预设 | 每次得手写 prompt | 场景 / 对方身份 / 语气,下拉点一下就行 |
| 「往专业偏」 | 描述很主观、靠感觉 | 5 根滑块量化控制 |
| Prompt 复用 | 收藏夹 / 自己存 | 内置可编辑的 Prompt 模板,含占位符 |
| 多模型对比 | 多开几个 Tab | 同一组配置接到不同 API Base,自由切换 |
| 隐私 | 取决于平台 | Key 仅在本机浏览器,前端直接打模型 API |
适合的场景:你已经有 OpenAI 兼容协议的模型 endpoint(自建的、公司内部的、SiliconFlow / DeepSeek / OpenRouter / 通义兼容模式等都行),又想要「多个版本一起出、肉眼比较」。
不适合的场景:你只想最方便地问个问题——那打开 ChatGPT 就完事了,没必要折腾这个。
三、它是怎么实现「并行多结果」的
很多人第一反应是:要不要后端做扇出?其实没必要。这个项目的做法是:
用
Promise.all把同一个 prompt、用 N 个不同的temperature一次性发给同一个模型。
核心逻辑就这么几行(位于 engine.js):
const base = ai.responseStyle === 'creative' ? 0.9
: ai.responseStyle === 'precise' ? 0.3
: 0.6;
const temps = [];
for (let i = 0; i < count; i++) {
// 围绕 base 在 [0.1, 1.2] 区间内对称扩散
temps.push(Math.min(1.2, Math.max(0.1, base + (i - (count - 1) / 2) * 0.22)));
}
const results = await Promise.all(
temps.map((t, i) => callOnce(prompt, model, t).then(text => ({
label: '候选 ' + (i + 1),
sub: '温度 ' + t.toFixed(2),
text,
})))
);简单可控:
- 「严谨」模式 base=0.3,3 个候选大概就是 0.08 / 0.30 / 0.52,三个偏稳的版本;
- 「灵活」模式 base=0.9,3 个候选大概就是 0.68 / 0.90 / 1.12,差异明显得多;
- 单个失败不影响整体:每个
callOnce都用.catch包了一层,单个候选挂掉只会显示「该候选生成失败」,其他的正常出来。
如果你没配模型,引擎会自动走一条本地演示通道:用一组正则把「根本跑不起来」「自己看下」这类硬话替换成柔和说法,再套上「结论先行版 / 委婉协作版 / 正式书面版 / 简洁直接版 / 共情关怀版」五种壳子合成出 N 个候选。纯规则、纯本地,0 网络请求——主要是为了让没有 Key 的访客也能直接看到「多结果对比」长什么样。
四、Prompt 模板长什么样
模型那一路用的是经典占位符模板,你可以在「配置 - 自定义提示词」里改:
你是一名资深的职场沟通顾问,擅长帮助技术同学优化沟通表达。
请在【完整保留原意】的前提下,将用户的原始表达改写得更得体、专业、有效。
【使用场景】{scene}
【沟通对象】{role}
【期望语气】{tones}
【优化维度强度】
{dimensions}
请只输出改写后的表达本身,不要任何额外说明。
【原始表达】
{text}运行时 {scene} / {role} / {tones} / {dimensions} / {text} 会被前端替换成当前选中的预设和滑块数值,例如 {dimensions} 实际渲染出来是这样的:
- 技术深度:50/100(0=通俗,100=专业)
- 术语密度:40/100(0=少用,100=充分)
- 信息详尽度:55/100(0=精简,100=详尽)
- 共情程度:60/100(0=克制,100=充分)
- 直接程度:50/100(0=含蓄,100=直接)把「主观的语感」翻译成「具体的数字」,在我个人体感里,比单写「请尽量委婉一些」可控得多。
五、技术栈与项目结构
故意没用任何框架,方便自己快速改,也方便别人 fork 走二改。
yanzhiyouli/
├── index.html // 仅页面骨架与抽屉/弹窗占位
├── styles.css // 全部样式(约 19KB,含响应式)
├── data.js // 出厂预设:场景 / 身份 / 语气 / 维度 / 默认 prompt
├── engine.js // 核心:buildPrompt / 远程并行 / 本地演示 / 统一入口 run()
├── app.js // 状态管理 + UI 渲染 + 事件 + localStorage 持久化
└── .with/
├── Dockerfile // nginx:1.27-alpine
└── nginx.conf // 监听 8000 端口数据流大致这样:
用户输入 ──► state(内存) ──► OptimizeEngine.run(payload)
▲ │
│ ▼
│ ┌───────────────────────────┐
│ │ 有可用模型? │
│ └────────┬───────┬──────────┘
│ │ │
│ 是 │ │ 否
│ ▼ ▼
│ Promise.all(N 个 temp) localMulti(规则合成)
│ │ │
└──── 渲染卡片 / 历史记录 ◄───── 候选数组(统一结构)任何一个小模块(PresetStore / HistoryStore / 配置抽屉 / 弹窗 / 渲染)都是独立函数,单文件代码量不大,扫一眼就能改。
六、本地跑起来(三种姿势)
姿势 1:双击 index.html
最暴力,绝大多数功能都能用,但部分浏览器在 file:// 协议下会限制 fetch,调远程模型 API 时可能直接被拦。所以这个方式一般只用来看 UI、看本地演示。
姿势 2:起个静态服务器
任何静态服务器都可以,比如:
# 任选其一
python3 -m http.server 8000
npx http-server -p 8000然后浏览器访问 http://localhost:8000。
姿势 3:Docker(线上同款)
仓库里自带 .with/Dockerfile 和 .with/nginx.conf,nginx 监听 8000:
docker build -t yanzhiyouli -f .with/Dockerfile .
docker run -d --name yanzhiyouli -p 8080:8000 yanzhiyouli
# 访问 http://localhost:8080线上 https://yzyl.codelong.top 就是这套镜像 + 反向代理 + HTTPS 证书,没有任何花活。
七、配置一个真实模型
打开右上角「配置」抽屉,新增一条模型,至少填四项:
| 字段 | 说明 | 例子 |
|---|---|---|
| name | 显示名,自己起 | DeepSeek-Chat |
| model | 真正下发给 API 的 model 字段 | deepseek-chat |
| apiBase | OpenAI 兼容前缀(不要带 /v1) | https://api.deepseek.com |
| apiKey | 你的 Key,只存浏览器 | sk-xxxxxxxx |
请求最终会拼成:
POST {apiBase}/v1/chat/completions
Authorization: Bearer {apiKey}
{
"model": "{model}",
"temperature": <自动生成>,
"messages": [{ "role": "user", "content": "<拼接好的 prompt>" }]
}只要它兼容 OpenAI Chat Completions 协议,理论上都能接:DeepSeek、SiliconFlow、OpenRouter、Together、自建的 vLLM / Ollama OpenAI 兼容端点……
八、踩坑提醒
1. apiBase 多写了 /v1
代码里会自己加 /v1/chat/completions,所以你只需要写到域名层级。如果你写成 https://api.xxx.com/v1,那最终请求就会变成 /v1/v1/chat/completions,404 给你看。
2. 浏览器跨域(CORS)
前端直接打模型 API,对方必须允许你的源(Origin)跨域。
- 主流公网模型服务(DeepSeek / OpenRouter / SiliconFlow 等)一般都允许;
- 自建的 vLLM / Ollama,需要在反向代理上加
Access-Control-Allow-Origin,不然 F12 里会看到 CORS 报错; - 实在搞不定,就自己起一个最简单的反代脚本,路径转发即可。
3. 用 file:// 双击直接访问,调不通模型
chrome 出于安全考虑会拦掉 file:// 下的部分 fetch。起个静态服务器或者用 Docker 跑,问题就没了。
4. Key 真的只在浏览器里
我没有后端,也不打算加后端。Key 全部存在 localStorage,所以:
- 别在公共电脑上保存;
- 清浏览器数据 = 清空 Key 和所有自定义预设,记得提前用「导出」按钮把 JSON 备份一下;
- 想换设备?「导出」一份 JSON,到新设备点「导入」即可,预设、模型、Prompt 模板一并迁移。
5. 候选数量 ≠ 越多越好
后台代码 clamp 在 [2, 5]。我自己日常用 3 就够了,5 个看花眼。每多一个候选就是多一次模型调用,账单也会多一份。
6. 历史记录最多保留 50 条
超出会从最旧开始丢。如果你有「想长期保存」的优秀改写,自己复制出来存别处,别指望它当云盘。
7. 自定义 Prompt 模板别把占位符删了{scene} {role} {tones} {dimensions} {text} 这五个占位符是运行时被替换的。如果你自定义模板时把 {text} 删了,模型就拿不到原文了,会很迷惑。
九、一些设计上的小决定
写完后回过头看,几个当时纠结过的点:
- 预设要不要写死? 写死最省事,但每个人的场景千差万别。最后选的是「内置一份出厂数据 + 用户自定义合并 + 本地持久化 + 一键导入导出」,弹性最大。
- 要不要用 React/Vue? 想了想,整个交互复杂度根本撑不起一套构建流程,原生 DOM 操作 + 一份扁平 state 已经够用,部署也省事,一份 nginx 镜像两百多 K。
- 要不要内置默认模型 / 默认 Key? 一开始有,后来全删了。原因有两个:①没人愿意把自己的 Key 放给陌生用户用;②有「本地演示」兜底,没 Key 的访客一样能体验「多结果对比」的核心交互。
- 多结果用不同模型并行 vs 同模型不同温度? 都试过。同模型不同温度的差异更稳定也更可控,不同模型并行容易出现「一个秒回、一个 30 秒还在转」的尴尬体感,对比体验反而下降。后续可能加一个「跨模型对比」的开关,但不是默认行为。
十、最后
线上地址再贴一次:https://yzyl.codelong.top
如果你也在做技术沟通这个方向、或者觉得「多候选并行 + 滑块量化」这个交互模式可以借鉴,欢迎随便 fork 和魔改。源码不长,过一遍大概十来分钟。
如果它在某次「我该怎么把这句话说得不那么冲」的时刻帮到你,那就值了。